Understanding the differences between Structured and Unstructured Data
With AI changing the way we look we data, and the impact on data management solutions, understanding the difference between data types is critical to ensuring the information contained with your systems are beneficial to users.
The four types of data
There are four main data structures:
Structured data is information that is formatted and organised for readability within relational databases. In contrast, unstructured data’s format is undefined, not well-organised, and not usable by relational databases.
Check out the KnowFirst™ API for more information
What is structured data?
Structured data refers to any data that is organised and stored in a predefined format that can be easily accessed, managed, and processed by computers. This means that the data is organised in a way that is consistent and easy to understand, with a clear structure and defined relationships between the different elements.
Structured data is typically stored in databases or spreadsheets, where each piece of information is assigned to a specific field or column, and the relationships between different pieces of data are defined by the way they are structured within the database. This makes it easy to query and analyse the data using tools such as SQL (Structured Query Language).
Some common examples of structured data include:
- customer records in a CRM system
- financial data in an accounting system, or
- inventory data in a warehouse management system.
Structured data accounts for approximately 20% of total global data and is particularly valuable to companies and investors. Although structured data is considered to be the most user-friendly and desirable data format, it is actually the least prevalent type of data structure. This is due to the fact that structured data is obtained from sources such as spreadsheets and relational database management systems.
Today we are seeing companies leverage the digitalisation of such structured data for building AI-based tools and data-driven decision-making.
What is unstructured data?
Structured data is often contrasted with unstructured data, which includes things like text documents, images, and video that are not easily organised into a structured format. It is not organised or formatted in a predefined data model and is stored as media files or in NoSQL databases.
Unstructured data accounts for approximately 80% of data worldwide, and despite its complexity, unstructured data, when integrated, organised, and analysed properly, provides companies with high-quality qualitative data and business insights.
Furthermore, unstructured data is obtained from a wide range of sources such as social media, documents, PDFs, audio files, video files, and sensor data, among others. However, due to the diverse types of sources and the lack of specific formatting requirements, unstructured data must be processed and converted before it can be effectively analysed or integrated.
The development of AI technology, automation, and cloud-based solutions has been crucial in handling unstructured data. In particular, unstructured data is stored on servers and in the cloud, and is managed using natural language processing and data mining techniques.
Interestingly, some companies still refuse to manage unstructured data, and simply expand their available storage space, filling it with more unstructured data.
What is semi-structured data?
Semi-structured data is a type of data that has some structure, but does not conform to the strict and rigid structure of structured data. Unlike structured data, which is organised into tables with predefined columns and data types, semi-structured data has a flexible structure that allows for variation in the way data is organised and stored.
Semi-structured data typically contains some form of metadata or tags that provide information about the structure of the data. This metadata allows the data to be easily searched and organised, even though the actual data itself may not be fully structured.
Common examples of semi-structured data include:
- XML files
- JSON files, and
- HTML documents,
- As well as log files and sensor data that may have some structure but also contain unstructured information.
Semi-structured data is often more flexible than structured data and can be easier to work with than unstructured data because it has some organisation and context.
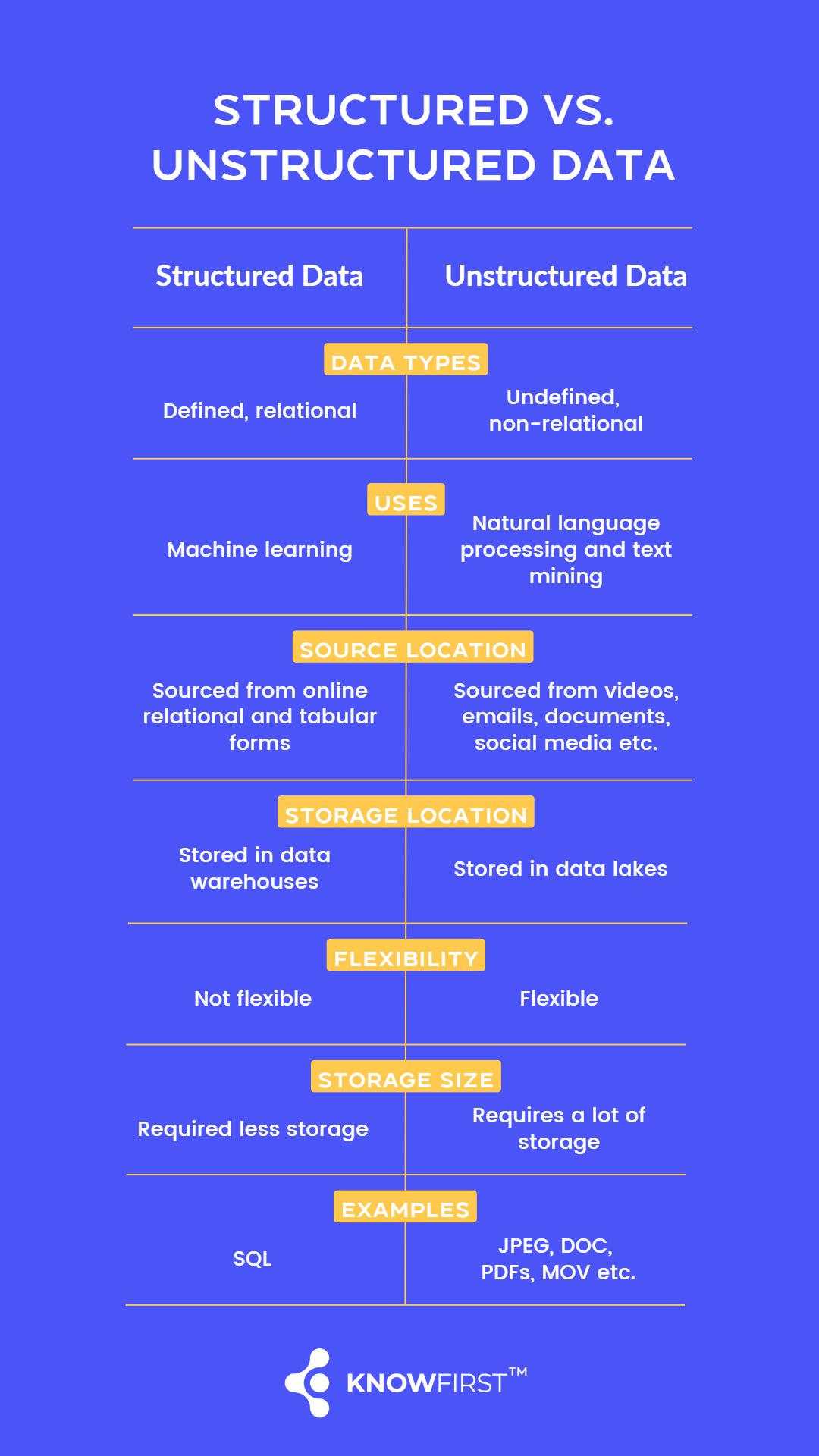
The key differences between Structured vs. Unstructured data
Structured data and unstructured data are two types of data that differ significantly in terms of their organisation, format, and usefulness. Here are some key differences between the two:
Organisation
Structured data is highly organised and conforms to a specific format, such as a database or spreadsheet. Unstructured data, on the other hand, has no specific organisation or structure, and may include data in the form of text, images, audio, or video files.
Accessibility
Structured data is typically more accessible and easier to analyse because it is organised in a specific format that can be easily searched and analysed using tools like SQL. Unstructured data, on the other hand, is more difficult to analyse and may require specialised tools and techniques.
Volume
Unstructured data tends to be larger in volume than structured data, as it includes a wide variety of data types and may be generated in large quantities, such as social media posts or sensor data.
Value
Structured data is typically considered more valuable than unstructured data because it can provide more accurate and reliable insights. However, unstructured data can also be valuable in certain contexts, such as sentiment analysis or image recognition.
Processing
Structured data can be easily processed and analysed by machines, while unstructured data requires more sophisticated processing techniques, such as natural language processing, to make sense of the data.
The Wrap Up
Having an understanding of the different types of data structures is crucial for companies to comprehend the significance of data management. To fully leverage the potential of data, companies must optimise their data management and storage processes for both structured and unstructured data.
As the amount of data being generated globally continues to increase exponentially, data scientists and companies will continue to enhance their management and storage capabilities to handle all types of data structures.


